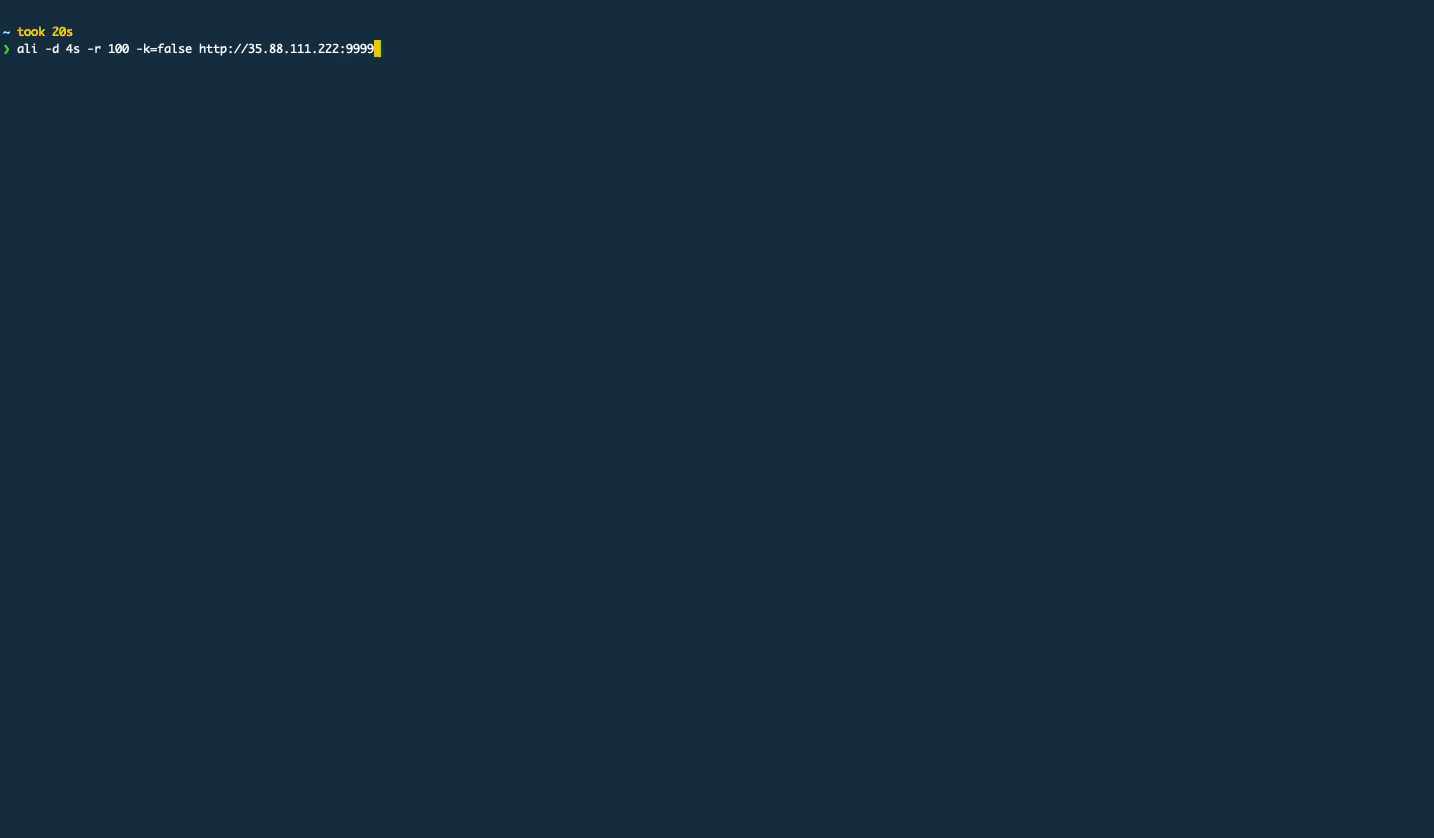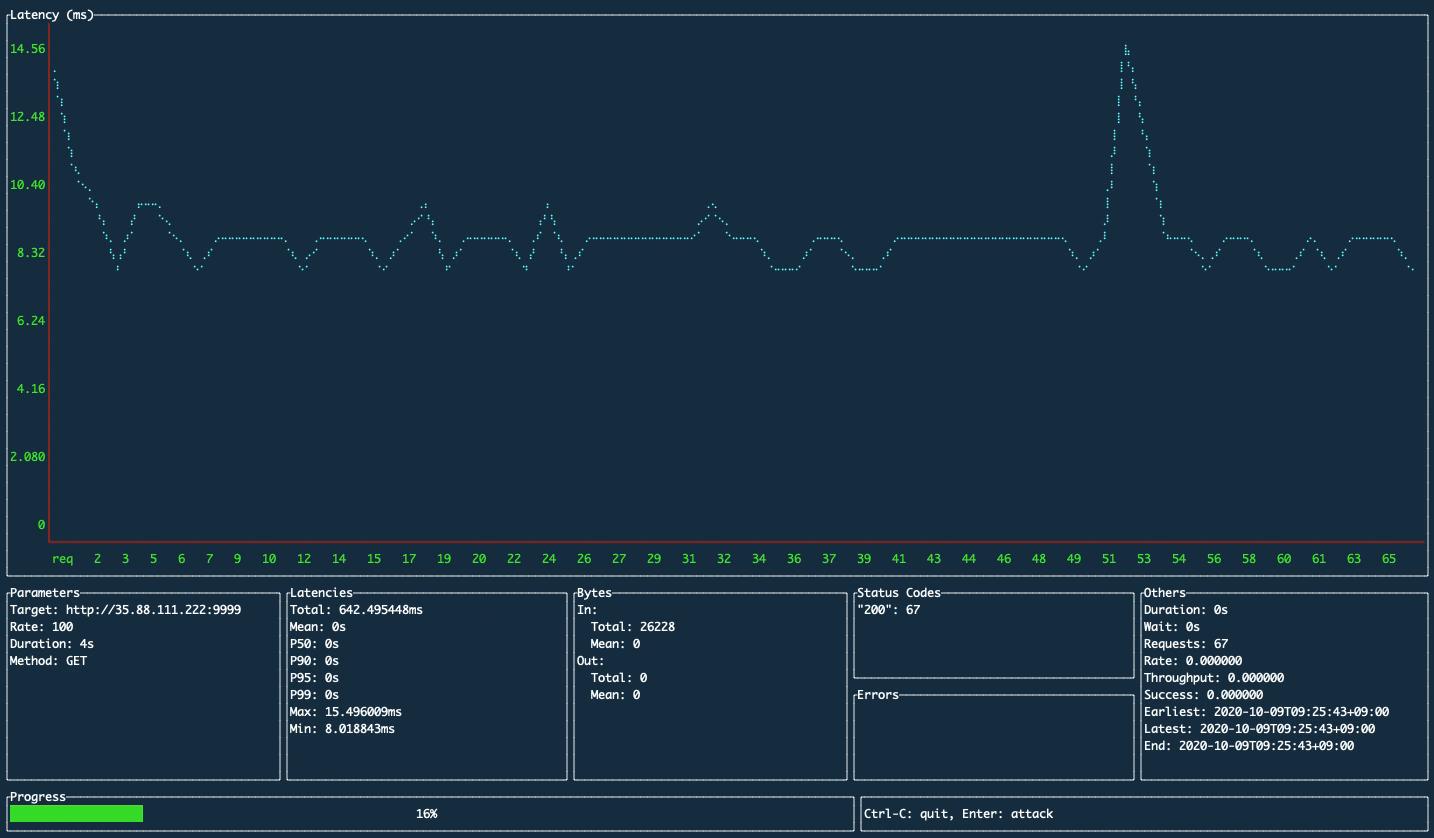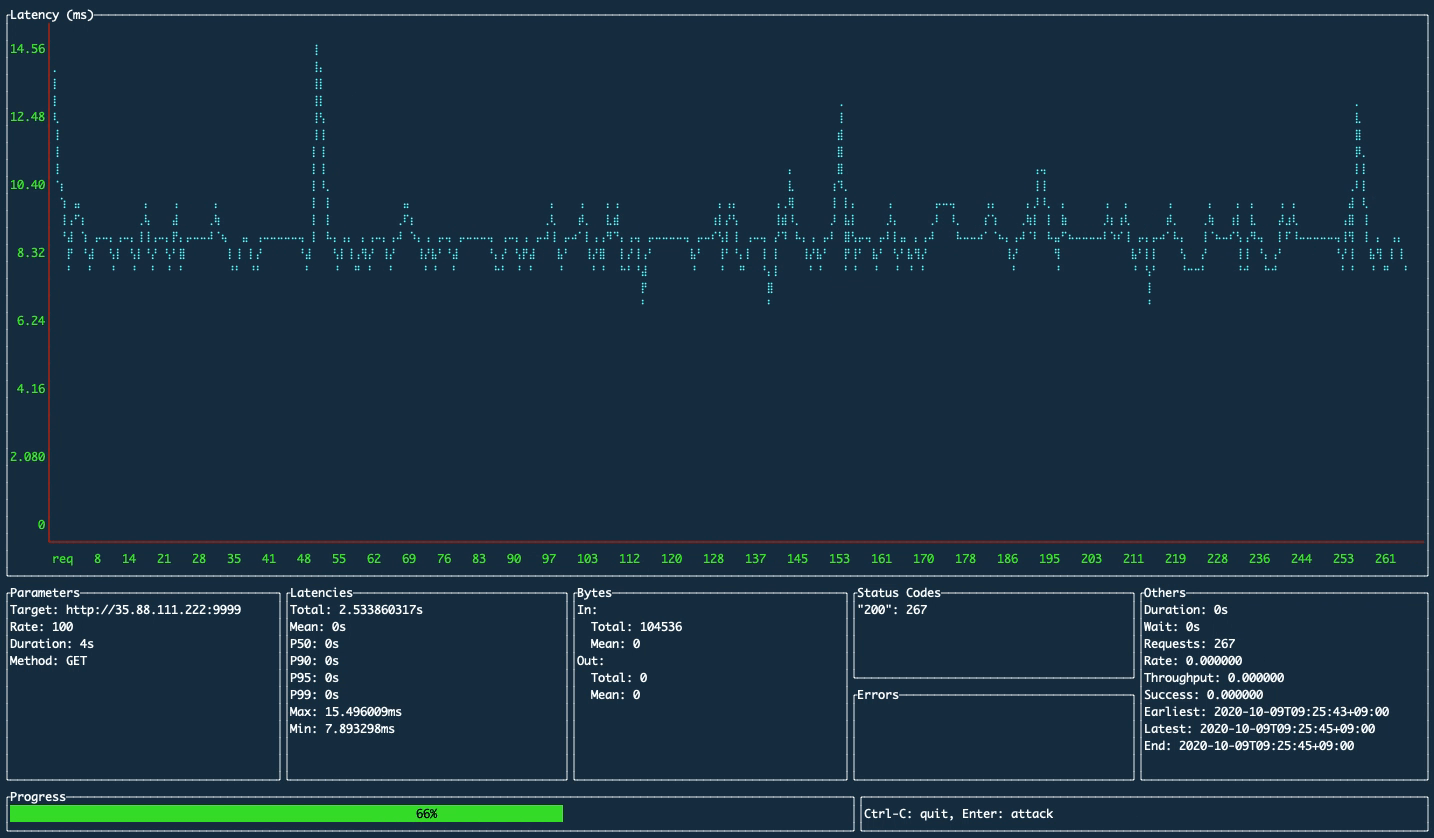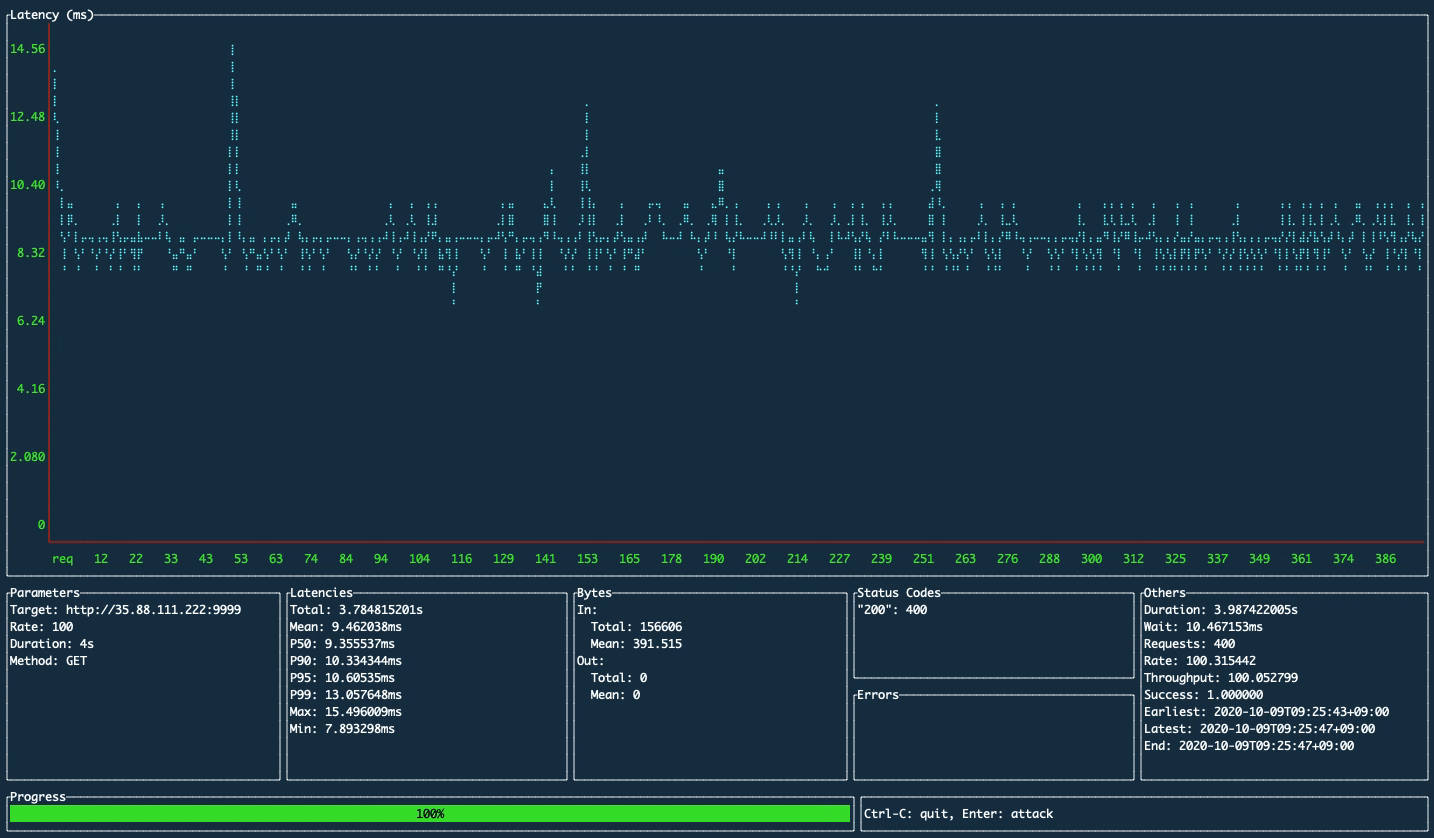
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
import os
import numpy as np
import torch
import onnx
import onnxruntime
batch_size = 5
x = torch.randn(batch_size, 3, 224, 224, requires_grad=True)
torch_out = torch_model(x)
torch.onnx.export(torch_model,
x,
"vit.onnx",
export_params=True,
opset_version=16,
do_constant_folding=True,
input_names = ['input'],
output_names = ['output'],
dynamic_axes={'input' : {0 : 'batch_size'},
'output' : {0 : 'batch_size'}})
onnx_model = onnx.load("vit.onnx")
onnx.checker.check_model(onnx_model)
num_logical_cpus = 4
sess_options = onnxruntime.SessionOptions()
sess_options.intra_op_num_threads = num_logical_cpus
ort_session = onnxruntime.InferenceSession("vit_quant.onnx", sess_options, providers=["CPUExecutionProvider"])
def to_numpy(tensor):
return tensor.detach().cpu().numpy() if tensor.requires_grad else tensor.cpu().numpy()
ort_inputs = {ort_session.get_inputs()[0].name: to_numpy(x)}
ort_outs = ort_session.run(None, ort_inputs); print(torch_out.detach().numpy(), "\n", ort_outs[0])
np.testing.assert_allclose(to_numpy(torch_out), ort_outs[0], rtol=1e-03, atol=1e-05)
print("Exported model has been tested with ONNXRuntime, and the result looks good!")
|